Co-founder of Storia AI, former Google Research engineer
Julia Turc
Profile
Julia Turc is one of those rare technologists who can build the thing, ship the thing, and then explain the thing — clearly — to people who weren’t in the room. She spent roughly eight years inside Google Research working on NLP, transfer learning, and Transformer efficiency, contributing to the kind of plumbing that quietly ends up in products billions of people touch: contextual retrieval work that fed into precursors of Gemini, on-device language tech for Google Keyboard and Pixel, and knowledge distillation methods for compressing big models into small ones. Her paper Well-Read Students Learn Better is still one of the standard references for how to distill BERT-class models without losing the plot.
In 2023 she left Google to co-found Storia AI, which went through Y Combinator’s Summer 2024 batch. Storia’s main product is Sage — an open-source AI copilot that ingests a codebase plus its surrounding documentation and tries to answer questions the way a senior engineer who actually knows the repo would. The framing matters: rather than another autocomplete wrapper, Storia is betting that the missing layer for developer AI is context grounding — knowing what your team’s code does, why it does it, and where the answers live across docs, issues, and Slack threads.
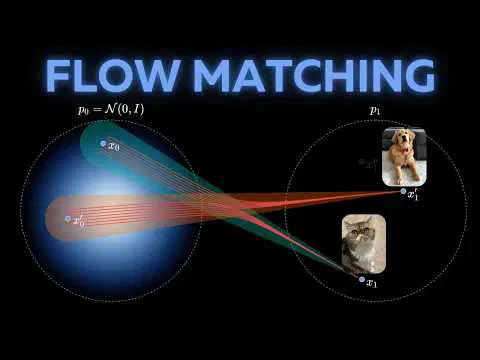
The other half of her work is education. Her YouTube channel describes itself as “anti-hype” AI explanation — Transformers, diffusion, distillation, quantization, walked through carefully enough that a curious generalist can follow without being insulted by hand-waving. The tone owes a clear debt to Andrej Karpathy’s “let me actually show you the code” style, but Turc brings a researcher’s instinct for what the field is overstating at any given moment, paired with a dry Eastern European skepticism toward Bay Area enthusiasm.
For developers learning AI today, she’s worth following because she sits at an unusually useful intersection: she’s done the production research work, she’s now building developer tooling on top of LLMs, and she can teach. That combination — researcher, founder, educator — is rarer than it should be, and it makes her explanations of things like RAG, distillation, or where Llama 4 actually fits in the stack land with more weight than the average AI YouTuber.
Key Articles & Papers
Well-Read Students Learn Better: On the Importance of Pre-training Compact Models Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation Measuring Attribution in Natural Language Generation Models Transformers, Explained: Understand the Model Behind GPT, BERT, and T5 From von Neumann to Memory-Augmented Neural Networks Fine-tuning DALL·E Mini (Craiyon) to Generate Blogpost Images Launch YC: Storia — A Contextual AI Pair ProgrammerVideos

YouTube